
목록DB (26)
송민준의 개발노트
 Oracle 비율 함수
Oracle 비율 함수
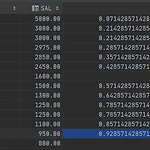
비율을 계산해주는 함수는 다음과 같다. 1. CUME_DIST 2. PERCENT_RANK 3. NTILE 4. RATIO_TO_REPORT 1. CUME_DIST - 파티션 전체 건수에서 현재 행보다 작거나 같은 건수에 대해 누적 백분율을 계산해주며 0과 1사이에 값이 분포해있다. select deptno, ename, sal, cume_dist() over(order by sal desc) as c_s from emp; 위 쿼리를 실행하면 백분율 처럼 나온다. 과거 학창시절 성적 백분율 나오는 그런거... 2. PERCENT_RANK - ANSI/ISO SQL 표준과 Oracle DBMS에서 지원해준다. - 파티션에서 제일 먼저 나온 것을 0, 제일 늦게 나온 것을 1로 하여 값이 아닌 행의 순서별 ..
 Oracle 행 함수
Oracle 행 함수
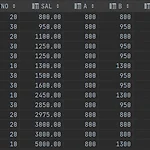
쿼리를 다루다보면 특정 행에 대해 다뤄야 할 때가 있다. 종류로는 1. FIRST_VALUE 2. LAST_VALUE 3. LAG 4. LEAD 위 4가지가 있다. 1. FIRST_VALUE : 파티션에서 가장 처음에 나오는 값을 구한다.(그룹함수 MIN과 같은 결과를 구할 수 있음) select deptno, sal, first_value(sal) over () as A, first_value(sal) over (partition by DEPTNO) as B, first_value(sal) over (partition by DEPTNO order by sal) as C, first_value(sal) over (partition by DEPTNO order by sal desc rows unbounde..
 Oracle 순위 함수(Rank) 사용법~!!!
Oracle 순위 함수(Rank) 사용법~!!!
순위 함수의 목적은 어떤 항목이나 파티션에 대해서 순위를 계산하는 함수이다~! 우선 랭크 함수의 종류는 1. RANK : 특정항목 및 파티션에 대해 순위를 계산한다. 만약 값이 같다면 순위 또한 같게 주어진다. 2. DENSE_RANK : 같은 순위일 경우 하나의 건수로 계산을 한다. 3. ROW_NUMBER : 같은 순위일 경우에도 고유의 순위를 부여한다. 위 3가지가 존재한다. 목적에 따라 사용하면 된다. 1. Partition by 사용에 따른 결과 비교 select ename, sal, rank() over (order by sal desc) all_rank, rank() over (partition by job order by sal desc) job_rank from emp; 위 쿼리를 실행하..
 oracle 개행 넣기
oracle 개행 넣기
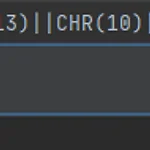
개발을 하다보면 DB에 개행이 들어가야 되는 경우가 있다. \n 위와 같은 방법 말고 또 뭐가 있을까? 그렇다 방법은 존재한다. select '1번'||chr(13)||chr(10)||'2번' from dual 위와 같은 쿼리를 실행해보면 아래와 같은 결과가 나온다. 반대로 제거를 하고싶다면? select replace(개행 들어간 내용, chr(13)||chr(10), '') from dual 위와 같이 해보면 개행을 제거할 수가 있다. 원리는 아스키코드를 변환하는 것인데 chr(13)의 경우 현재 줄안에서 커서 위치를 맨 앞으로 옮기는 것이고 chr(10)의 경우 커서 위치를 아래로 가게 하는 것이다.(개행) 결과적으로 개행이 되는 것
기본적으로 쿼리를 짜다보면 b 테이블에 있는 값을 불러오든 처리해서 불러오든 가져와야 하는 경우가 있다. 프로시저를 짜는 것도 하나의 방법이지만 비효율적이고 시간도 더 나오는 것 같다.(테스트 해보니 최소 1.4배...?) update 문을 좀 더 활용해서 해보면 구조는 아래와 같다. update 테이블A a set (a.칼럼1, a.칼럼2, a.칼럼3) = (select sum(b.칼럼1) , sum(b.칼럼2) , sum(b.칼럼3) from 테이블B b where b.키값1 = a.키값1 and b.키값2 = a.키값2) where a.조건1 = '조건값1' and a.조건2 = '조건값2' 위 update 문에서 좀 더 좋은 방법은 아래와 같다.(시간 단축 튜닝) update ( select a...
 (Oracle)윈도우 함수 사용법
(Oracle)윈도우 함수 사용법
자. 윈도우 함수란 무엇인가? 분석함수 중에서 윈도우절을 사용하는 함수를 뜻한다! 윈도우 함수를 사용해서 합계, 순위, 행 위치 등을 컨트롤 가능하다. 구조는 다음과 같다. SELECT 윈도우함수(파람) OVER(PARTITION BY 칼람 ORDER BY WINDOWING) - 윈도우 함수 구조 1. 파람 : 윈도우 함수에 따라 0~ 여러개의 파람을 가진다. 2. PARTITION BY : 전체 집합을 기준에 의해 소그룹으로 나눔 3. ORDER BY : 정렬 4. WINDOWING : 행 기준의 범위를 정함 1) ROWS : 부분집합인 윈도우 크기를 물리적 단위로 행의 집합을 지정 2) RANGE : 논리적인 주소에 의해 행 집합을 지정함 3) BETWEEN A AND B : A와 B 사이의 집합 4..
 그룹 함수
그룹 함수
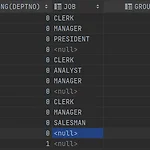
1. ROLLUP ROLLUP이란 GROUP BY를 한 칼람에 대하여 Subsum을 해준다. ROLLUP은 여러개의 컬럼에도 적용이 가능하다. 그리고 적용한 대상에는 null 값이 들어가는데 아래와 같이 활용이 가능하다. SELECT DECODE(DEPTNO, NULL, 'DEPT_SUM',DEPTNO), SUM FROM EMP GROUP BY ROLLUP(DEPTNO) 위 쿼리는 EMP테이블에 DEPTNO 별 Subsum이 포함이 되는 SUM을 보여준다.(물론 sum 함수를 써야함) 2개 이상을 활용할 경우 SELECT DECODE(DEPTNO, NULL, 'Allsum', DECODE(GRADE, NULL, 'Subsum', DEPTNO)), GRADE, SUM(SAL) FROM EMP GROUP B..
Subquery란 SELECT문 내에서 다시 SELECT문을 사용하는 것이다. 형태는 ① FROM 구에 SELECT문을 사용하는 인라인 뷰와 ② SELECT에 사용하는 스칼라 서브쿼리(Scala Subquery), ③ WHERE에 사용하는 서브쿼리 등이 있다. 예시를 들어보겠다. ① 인라인 뷰(from) - FROM 구에 일종의 가상의 테이블(뷰)를 만들어 사용하는 것이다. // EMP에 순번을 매겨 10번 이하까지 구하는 쿼리 SELECT * FROM ( SELECT ROWNUM NUM, ENAME FROM EMP ) a WHERE NUM < 10; ② 스칼라(select) - 스칼라 Subquery는 반드시 한 행과 한 칼럼만 반환하는 서브쿼리이다. (여러행이면 에러뜸) // 회원별 급여와 상급자의 ..